Scraping with Scrapy
Created On 07. Apr 2020
Updated: 2021-05-01 23:54:09.472016000 +0000
Created By: acidghost
We can use Scrapy to parse a website. Scrapy is an open source framework that can be used as base for spidering scripts.
Install scrapy with pip:
$ scrapy pip install
After let's inspect one of my sites with the interactive shell
$ scrapy shell 'http://mechaplay.com'
NOTE: on Windows you will need double quotes
Alright, since we landed on the main page, let's grab our text like this
>>> response.xpath('//div[@class="index-entry-content"]/p[1]/text()').extract()
Looks creepy, but it isn't. Scrapy uses Xpath to scrape through the site's nodes. XPath is a syntax that defines XML elements also is used to navigate through them.
Further we get our div class "index-entry-content" where the text is situated and specify that we want to get the text from the tags. We finalise it by appending "extract" which gets all elements on the page.
Scrapy can scrape pages also through CSS selectors. We would scrape the previous page like this:
>>> response.css('div.index-entry-content p:nth-child(1)::text').extract()
Generally CSS is easier, but XPath more powerful.
The interactive shell is a nice way to practice navigating through sites elements. Use a browser like Firefox, inspect the elements and have fun learning!
More plain example is:
>>> response.xpath('//div').extract
From here you can expand the path and drill deeper into the nodes, like I did earlier.
Creating Spiders
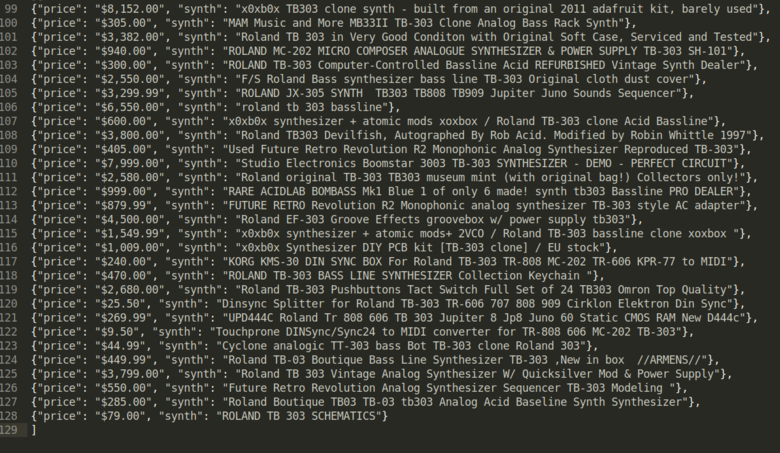
We can automate the scraping process by building spiders. For this example, I will show how to scrape through a specific search keyword on ebay, and output the results from the page, where the name of the item and price will be displayed. Please note however, that ebay is against such actions, and this is just for demonstrative purposes. I will not get into details, but generally, as a business they are against unauthorized competitive actions. We are not misusing in any way their information, couldn't be mass producing a synth that was discontinued in 1984, as shown in the example below. If you want to get the information from ebay in such way, check out their API. Okay, now let's do it!
Fire this command to create a new spider:
$ scrapy ebayItems Spider
Spiders are created inside the generated projects like we did above. Go there:
$ cd Spider
Then generate a spider command:
$ Scrapy genspider ebay ebay.com
You will see another folder called ‘spiders’. Open the items.py and define a new subclass
from scrapy.item import Item, Field
class EbayitemsItem(Item):
# define the fields for your item here like:
synth = Field()
price = Field()
Inside the ebay.py import the following
from scrapy.spiders import Spider
from scrapy.selector import Selector
from pprint import pprint
from ebayItems.items import EbayitemsItem
then define the url for crawling. Here I am looking for a tb-303 synth:
class EbaySpider(Spider):
name = 'ebay'
allowed_domains = ['ebay.com']
start_urls = ['http://ebay.com/sch/i.html?_nkw=tb-303']
After that we need to define a parse method:
# Define parse
def parse(self, response):
price=response.xpath('//div[@class="s-item__detail s-item__detail--primary"]/span[@class="s-item__price"]/text()').extract()
synth=response.xpath('//div[@class="s-item__info clearfix"]/a[@class="s-item__link"]/h3[@class="s-item__title"]/text()').extract()
items = []
then we are mapping our fields from items.py and appending the output:
for synth, price in zip(synth,price):
item = EbayitemsItem()
item['synth'] = synth
item['price'] = price
items.append(item)
return items
now execute this command to run the spider and output it in json format:
$ scrapy crawl ebay --output result.json
This way Scrapy will pass the crawled urls to the testSpiderItems with new instance for each.
Viewing this in editor, I see some nice synths on display :shipit:
Section: Web
Back